
사진이 저렇지만, 뭐 하기 싫은데 한다는 의미의 느낌은 전혀 아닙니다.
혼공단도 처음이고, 블로그도 거의 처음인데, 잘 봐주세요. 🙇🏻
정리하면서 많이 듣고 있는 노래를 하나 공유하면서 시작하겠습니다.
[혼공머신] 로드맵

개정판에서 달라진 점
- 대규모 언어 모델에 대한 장 추가
- BART, KoBART, EXAONE, GPT-4
- 파이토치 코드로 작성된 예제 제공
- 7-9장
- 자주 묻는 질문 추가
- 확인 문제 보강
- 분량이 약 30% 증가
01-1 인공지능과 머신러닝, 딥러닝
인공지능이란?
인공지능 태동기
- 인공지능(Artificial Intelligence)은 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
- 1943년, 워런 매컬러와 월터 피츠의 "A Logical Calculus of the Ideas Immanent in Nervous Activity"라는 논문에서 신경계를 단순한 논리 요소들의 네트워크로 보는 수학적 모델
- 1950년, 앨런 튜링이 인공지능이 사람과 같은 지능을 가졌는지 테스트할 수 있는 "튜링 테스트" 발표
- 1956년, 다트머신 AI 컨퍼런스에서 인공지능에 대한 전망이 최고조에 달함
인공지능 황금기
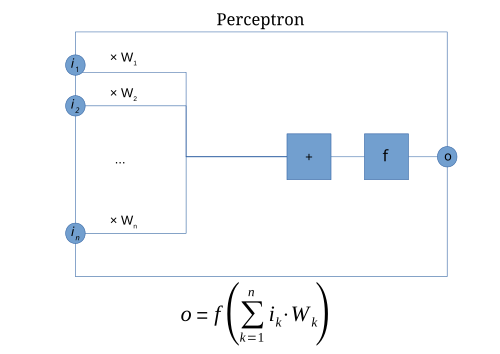
- 1957년 프랑크 로젠블라트가 로지스틱 회귀의 초기 버전이라 볼 수 있는 퍼셉트론 발표
- 1959년 데이비드 허블과 토르스텐 비셀이 고양이를 사용해 시각 피질에 있는 뉴런 기능 연구
1차 AI 겨울
- 1974년~1980년
AI 붐
- 전문가 시스템
2차 AI 겨울
- 전문가 시스템의 한계로 2차 AI 겨울 도래
LeNet-5

- 1998년 얀 르쿤이 LeNet-5라고 하는 최초의 합성곱 신경망을 통해 손글씨 숫자를 인식하는데 성공
AlexNet
- 이미지 분류 대회인 ImageNet에서 합성곱 신경망 AlexNet 사용
텐서플로

- 2015년 구글이 출시
- 텐서플로는 구글에서 개발한 오픈소스 딥러닝 프레임워크로, 머신러닝 모델을 만들고 훈련시키는 데 사용
- 데이터를 '텐서'라는 다차원 배열로 처리하며, 인공지능, 자연어 처리, 이미지 인식 등 다양한 분야에 활용
알파고

- 2016년 출시
- 알파고(AlphaGo)는 구글 딥마인드가 개발한 인공지능 바둑 프로그램으로, 2016년 세계적인 바둑 기사 이세돌 9단과의 대결에서 승리하며 인공지능의 뛰어난 능력을 입증
강인공지능과 약인공지능
- 영화 '그녀'의 사만다나 '터미네이터'의 스카이넷처럼 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템을 인공일반지능 혹은 강인공지능이라고 함
- 현실에서 애플의 '시리'나 자율 주행 자동차 등 특정 분야에서 사람의 일을 도와주는 보조 역할만 가능한 인공지능을 약인공지능이라고 한다.
인공지능이란
- 머신러닝, 신경과학, 로봇과학, 최적화 등이 복합적으로 관여하는 것이 인공지능
- 머신러닝은 인공지능의 하위 개념으로, 데이터를 바탕으로 패턴을 파악해 작업 수행을 자동화하는 알고리즘
- 대표적 라이브러리: 사이킷런; 선형회귀, 로지스틱 회귀, 결정 트리, 랜덤 포레스트 등
- 수많은 머신러닝 알고리즘 중에 인공 신경망 알고리즘을 기반으로 한 방법들을 통칭하여 딥러닝
- 대표적 라이브러리(Keras, Pytorch): CNN(합성곱 신경망), RNN(순환 신경망), 트랜스포머 등
01-2 코랩과 주피터 노트북
구글 코랩

- 구글이 대화식 프로그래밍 환경인 주피터를 커스터마이징한 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스.
텍스트 셀

- 셀은 코랩에서 실행할 수 있는 최소 단위
- 텍스트 셀은 코드처럼 실행되는 것이 아니기 때문에 자유롭게 사용 가능.
- HTML과 마크다운을 혼용해서 사용 가능.
코드 셀

- 코드를 실핼할 수 있다.
노트북
- 구글 클라우드의 컴퓨트 엔진에 연결되어 있고, 가상 서버를 사용한다.
1-2 확인 문제
- 구글에서 제공하는 웹 브라우저 기반의 파이썬 실행 환경은 무엇인가요?
정답: 코랩 - 코랩 노트북에서 쓸 수 있는 마크다운 중에서 기울임 꼴로 쓰는 것은?
정답: _혼공머신_ - 코랩 노트북은 어디에서 실행되나요?
정답: 구글 클라우드
01-3 마켓과 머신러닝
생선 분류 문제
프로그램으로 생선을 분류한다고 가정하자.
- 머신러닝으로 기준을 찾고, 그 기준을 활용해 생선이 도미인지 아닌지 판별 가능하게 한다.
- 분류: 여러 개의 클래스 중 하나를 구별해 내는 문제
- 이 생선 분류 문제처럼, 2개의 클래스 중 하나를 고르는 문제를 이중 분류
도미 데이터 준비하기
- 도미의 길이와 무게를 파이썬 리스트로 만들어서 만든다.
- 생선의 길이와 무게와 같은 특징들을 특성이라고 한다.

- 특성을 그래프로 표현해 데이터를 더 잘 이해하고 활용하기 위해 산점도로 표시한다.
- 파이썬에서 과학계산용 그래프를 그리는 대표적 패키지는 matplotlib
- 파이썬 패키지는 import를 통해 불러와 활용할 수 있음.
- as 키워드를 통해 해당 패키지를 줄여서 쓸 수 있다.
- ex) matplot -> plt, numpy -> np

- 산점도 그래프가 일직선에 가까운 형태로 나타나는 경우 선형적이라고 한다.

빙어 데이터 준비하기

- 데이터를 입력해 하나의 산점도에 표현하게 되면, 두 항목의 색을 구분해서 나타내준다.

첫 번째 머신러닝 프로그램
- k-최근접 이웃 알고리즘은 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용.
- 살펴볼 데이터만 있으면 되지만 데이터가 아주 많으면 메모리가 필요하고, 직선거리를 계산하는 데 시간이 많이 든다.
- 참고할 데이터 수의 기본값은 5로, n_neighbors 파라미터로 기준을 바꿀 수 있다.
- 사이킷런 패키지를 사용하기 위해 2차원 리스트를 만든다.
- k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트 후 해당 클래스의 객체 생성
- fit() 메서드를 사용해 도미를 찾기 위한 기준을 학습시키는데 이 과정을 훈련
- score() 메서드를 사용해 모델을 평가할 수 있고, 정확도라고 하는 값을 리턴
- predict() 메서드를 사용해 새로운 데이터의 정답을 예측
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
length = bream_length + smelt_length
weight = bream_weight + smelt_weight
fish_data = [[l, w] for l, w in zip(length, weight)]
fish_target = [1] * 35 + [0] * 14 # bream == 1, smelt == 0
from sklearn.neighbors import KNeighborsClassifier # k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier를 임포트
kn = KNeighborsClassifier() # KNeighborsClassifier의 객체 생성
kn.fit(fish_data, fish_target) # 도미를 찾기 위한 기준을 학습시키는데 이 과정을 훈련
kn.score(fish_data, fish_target) # 모델을 평가할 수 있고, 정확도라고 하는 값을 리턴
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.scatter(30, 600, marker='^') # length == 30, weight == 600 인 물고기
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
kn.predict([[30, 600]]) # length == 30, weight == 600 인 물고기가 무엇인지 예측.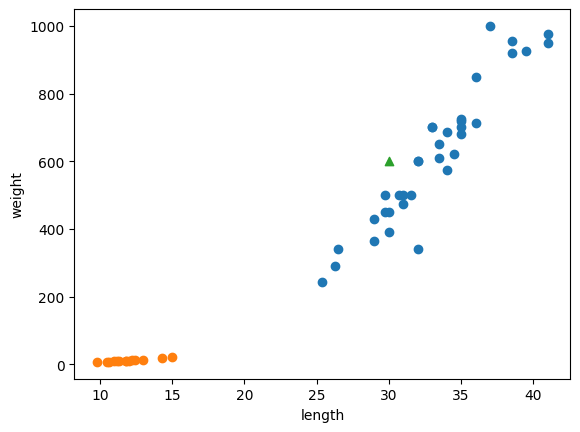
코드를 실행한 결과인 산개도를 보면, 길이 30, 몸무게 600의 물고기는 도미로 판별났다.
1-3 확인 문제
- 데이터를 표현하는 하나의 성질로써, 예를 들어 국가 데이터의 경우 인구 수, GDP, 면적 등이 하나의 국가를 나타냅니다. 머신러닝에서 이런 성질을 무엇이라고 부르나요?
정답: 특성 - 가장 가까운 이웃을 참고하여 정답을 예측하는 알고리즘이 구현된 사이킷런 클래스는 무엇인가요?
정답: KNeighborsClassifier - 사이킷런 모델을 훈련할 때 사용하는 메서드는 어떤 것인가요?
정답: fit() - 모델의 정확도를 계산하는 방법은?
정답: (정확히 맞힌 개수) / (전체 데이터 개수)
02-1 훈련세트와 테스트세트
지도학습과 비지도 학습
- 지도 학습은 훈련하기 위한 데이터와 정답이 필요하고, 이를 입력과 타깃이라고 하며, 합쳐서 훈련 데이터라고 한다.
- 정답이 있으니 알고리즘이 정답을 맞히는 것을 학습한다.
- 비지도 학습은 타깃 없이 입력 데이터만 사용하기에 무언가를 맞힐 수 없다. 데이터를 잘 파악하거나 변형하는데 도움을 준다.
훈련세트와 테스트 세트
- 머신러닝 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 평가에 사용할 데이터가 각각 달라야 한다.
- 평가를 위해 또 다른 데이터를 준비하거나, 이미 준비된 데이터 중에서 일부를 떼어내어 활용
- 평가에 사용하는 데이터를 테스트 세트, 훈련에 사용되는 데이터를 훈련세트라고 한다.
- 각 생선의 길이와 무게를 하나의 리스트로 만들고 이와 같은 데이터를 샘플이라고 한다.
- 리스트처럼 배열의 요소를 선택할 때는 배열의 위치, 즉 인덱스를 지정한다.
- 인덱스 외에도 슬라이싱이라는 연산자를 통해서 인덱스의 범위를 지정해 원소를 선택할 수 있다.
- 하지만 슬라이싱은 마지막 인덱스의 원소는 포함되지 않는다.
샘플링 편향
- 훈련하는 데이터와 테스트하는 데이터에는 도미와 빙어가 골고루 섞여 있어야 한다.
- 일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 한다.
- 골고루 샘플을 뽑거나 데이터 세트를 나누기 전에 섞기 위해 파이썬의 대표적인 배열 라이브러리인 numpy를 활용한다.
넘파이
- 넘파이 배열은 핵심 부분이 C, C++과 같은 저수준 언어로 개발되어 빠르고, 데이터 과학 분야에 알맞게 최적화되어 있기에 사용,
- 파이썬 리스트를 넘파이 배열로 만들기 위해 array() 함수에 파이썬 리스트를 전달한다
- 넘파이 배열의 크기를 알기 위해서는 shape 속성을 사용
- 입력과 타깃을 같은 위치에 있어야 하기 때문에 넘파이의 arrange() 함수를 사용해 인덱스를 만든다.
- shuffle() 함수를 통해 인덱스를 무작위로 섞고, 입력과 타깃에 전달하여 랜덤하게 훈련 세트와 테스트 세트를 만든다.
두 번째 머신러닝 프로그램
# 생선의 길이와 무게 리스트
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
fish_data = [[l, w] for l, w in zip(fish_length, fish_weight)]
fish_target = [1]*35 + [0]*14
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
import numpy as np
# 리스트를 넘파이 배열로 변환
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)
# 인덱스를 무작위로 섞는다
np.random.seed(42)
index = np.arange(49)
np.random.shuffle(index)
# 랜덤하게 35개의 샘플을 훈련 세트
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]
# 랜덤하게 14개의 샘플을 테스트 세트
test_input = input_arr[index[35:]]
test_target = target_arr[index[35:]]
# 산점도 그래프 생성
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(test_input[:, 0], test_input[:, 1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
print(kn.predict(test_input))
print(test_target)
확인 문제
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃을 알고 있을 때 사용할 수 있는 학습 방법은?
정답: 지도 학습 - 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상은?
정답: 샘플링 편향 - 사이킷런은 입력 데이터가 어떻게 구성되어 있을 것으로 기대하나요?
정답: 행: 샘플, 열: 특성 - 배열 arr에서 두 번째 원소에서부터 다섯 번째 원소까지 선택하기 위한 방법은?
정답: arr[1:5]
02-2 데이터 전처리
넘파이로 데이터 준비하기.
- 넘파이의 column_stack() 함수를 사용하면, 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결한다.
- 넘파이의 ones() 함수와 zeros() 함수를 통해 원하는 개수의 1과 0을 채운 배열을 만들어 타깃 데이터를 만들 수 있다.
사이킷런으로 훈련세트와 테스트 세트 나누기
- 사이킷런 model_section 모듈 아래에 있는 train_test_split() 함수는 함수로 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어 준다.
- train_test_split() 함수에는 자체적으로 랜덤 시드를 지정할 수 있는 random_state 파라미터가 있다.
- train_test_split() 함수의 stratify 파라미터에 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눌 수 있어 훈련 데이터가 작거나 특정 클래스의 샘플 개수가 적을 때 샘플링 편향을 줄일 수 있다.
수상한 도미 한 마리, 기준을 맞춰라
- 산점도의 그래프에 나타난 거리 비율이 다르기에, 어느 한 축으로 거리가 조금만 멀어져도 아주 큰 값으로 계산된다.
- 특성의 값이 놓인 범위가 다를 때, 특성의 스케일이 다르다고도 한다.
- 데이터를 표현하는 기준이 다르면 알고리즘이 올바르게 예측할 수 없기에 (특히 거리 기반일 때), 제대로 사용하려면 특성값을 일정한 기준에 맞춰 주어야 하는데 이를 데이터 전처리라고 한다.
- 가장 널리 사용하는 전처리 방법 중 하나는 표준점수로, 각 특성 값이 평균에서 표준편차의 몇 배만큼 떨어져 있는지를 나타낸다.
- 분산은 데이터에서 평균을 뺀 값을 모두 제곱한 다음 평균을 내어 구하고, 표준편차는 분산의 제곱근.
- 데이터를 표준점수로 변환하는 과정을 표준화라고 한다.
- np.mean() 함수로 평균을 계산하고, np.std() 함수로 표준 편차를 계산한다.
- 특성마다 값의 스케일이 다르고 평균과 표준편차는 각 특성별로 계산해야 하기에 axis=0으로 지정.
- 넘파이에서 산술 연산 대상이 되는 배열들의 모양이 다른 경우에도, 연산이 가능하도록 배열들의 모양을 처리하는 방법을 브로드캐스팅이라고 한다.
브로드캐스팅 조건
- 둘 중 하나의 배열이 1차원 배열인 경우
- 두 배열의 짝이 맞을 때
- 두 배열이 뒤에서 부터 대응하는 축의 크기가 동일하거나, 1이어야만 한다.
전처리 데이터로 모델 훈련하기
- 샘플을 동일한 비율로 변환해줘야 하는데, 훈련 세트의 mean, std를 이용해서 변환해야 한다.
- 훈련을 마치고 테스트 세트로 평가할 때는, 테스트 세트도 훈련 세트의 평균과 표준편차로 변환해야 하기 때문에 이를 주의해야 한다.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
import numpy as np
fish_data = np.column_stack((fish_length, fish_weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, random_state=42)
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state=42)
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
new = ([25, 150] - mean) / std
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_scaled, train_target)
test_scaled = (test_input - mean) / std
distances, indexes = kn.kneighbors([new])
import matplotlib.pyplot as plt
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker='^')
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()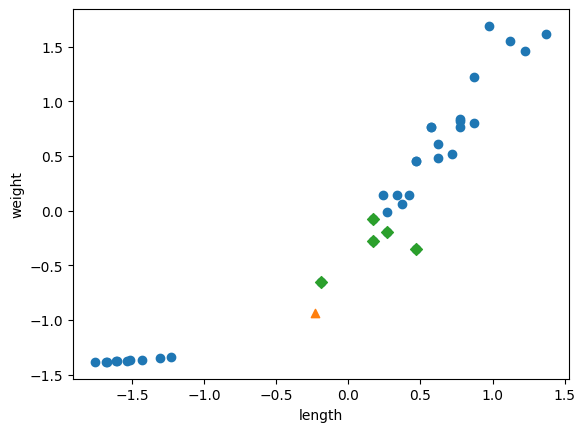
확인문제
- 이 방식은 스케일 조정 방식의 하나로 특성값을 평균에서 표준편차의 몇 배수만큼 떨어져 있는지로 변환한 값은?
정답: 표준점수 - 테스트 세트의 스케일을 조정하려고 할 때, 어떤 데이터의 통계 값을 사용해야 하나요?
정답: 훈련세트 - for 반복문을 사용하지 않고 넘파이의 배열의 모든 원소에 대해 산술 연산이 적용되는 기능이 무엇인가요?
정답: 브로드캐스팅
'머신러닝' 카테고리의 다른 글
| [혼공머신] 3. 🛝🌞🫠 (4) | 2025.07.21 |
|---|---|
| [혼공머신] 2. 🤷🏻♂️😵💫🌀 (2) | 2025.07.13 |